

了解了一下强化学习
相关资料:
pytorch tutorials里的强化学习教程:REINFORCEMENT LEARNING (DQN) TUTORIAL
伯克利的CS294-112(英文字幕):https://www.bilibili.com/video/av20957290
相关博客:学到了!UC Berkeley CS 294深度强化学习课程(附视频与PPT)
心路历程:
先读了一遍 pytorch tutorials里的代码,运行了一遍。效果如下:
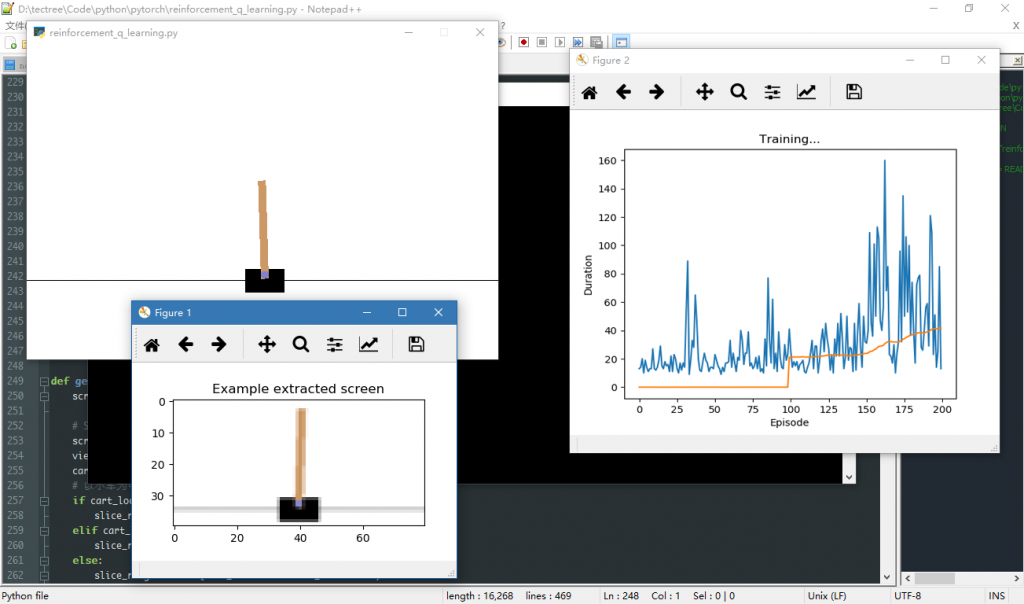
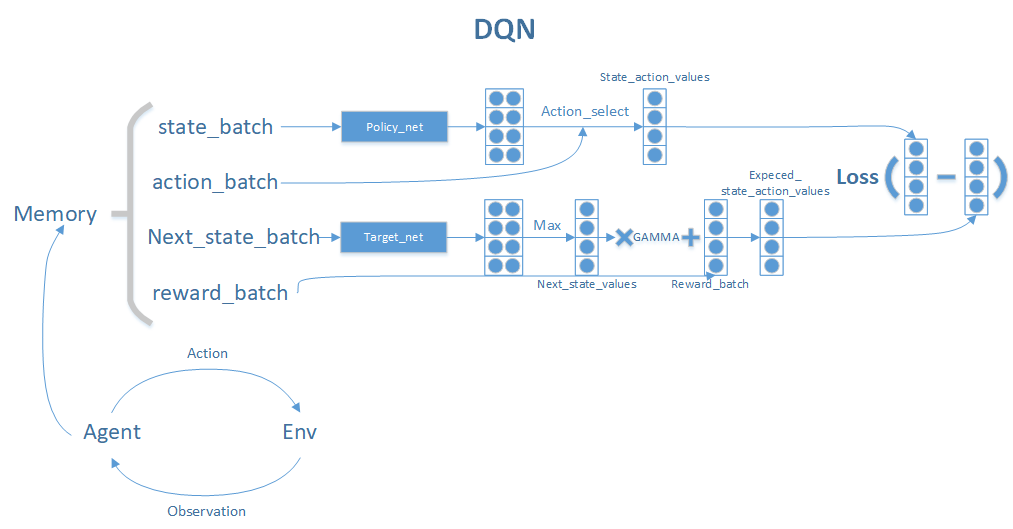
把代码里的训练过程总结成一张图:
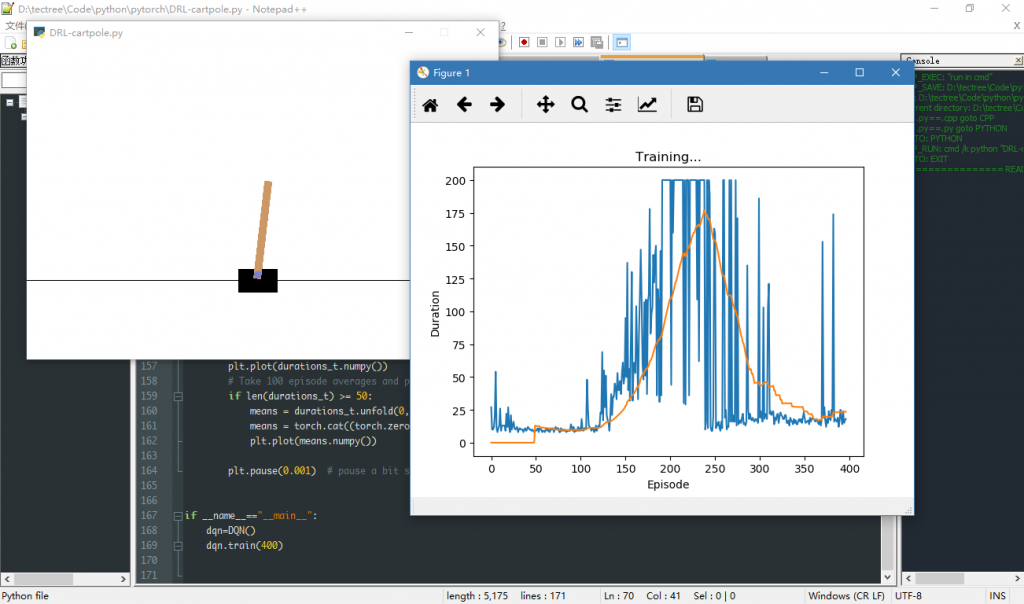
自己重新实现:
官网的toturial用的是屏幕截到的图像信息,我使用gym里面直接返回的observation(小车位置,小车速度,木棒角度,木棒角速度)重新写了一遍。改动了网络结构、训练过程以及增加了升维降维等乱搞:
网络结构:
class Net(nn.Module): def __init__(self): super(DQN.Net,self).__init__() self.fc1=nn.Linear(12,16) # self.bn1=nn.BatchNorm1d(8) self.fc2=nn.Linear(16,16) # self.bn2=nn.BatchNorm1d(16) self.fc3=nn.Linear(16,2) def forward(self,x): # x=F.relu(self.bn1(self.fc1(x))) # x=F.relu(self.bn2(self.fc2(x))) x=torch.cat([x,pow(x,2),0.1/x],1) x=F.relu(self.fc1(x)) x=F.relu(self.fc2(x)) x=self.fc3(x) return x
把卷积层全换成全连接层,去掉了BatchNorm(Linear不能接BatchNorm?)。
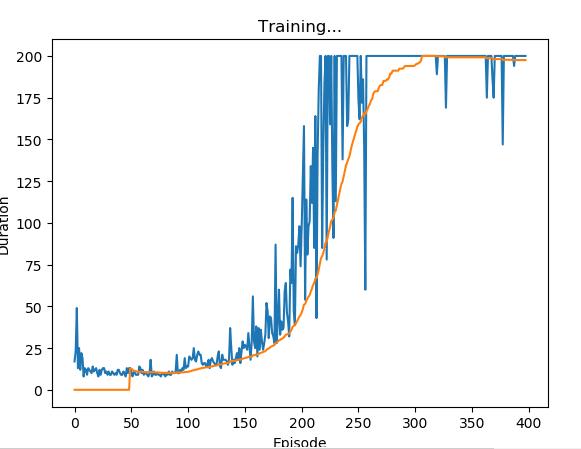
直接使用环境返回的observation效果好了很多,但也发现一个严重的问题:模型训到一般效果突然开始雪崩(见下图)。后来发现是官网tutorial里训练过程的代码有bug。
问题来源及解决方法:问题来自于这个小车游戏在200个step(duration)后会强行终止(给done=True),这个和棒子倒下去GG是一个信号,引发一连串反应:
- next_state=None
- 训练时expect_state_value=0
这样时间一长会模型会学到第200轮的估价为0的结果。解决方法就是加特判,给第200轮加一个很大的回报,然后就稳定了:
if turns==199: reward+=400
代码文件:
import gym
import math
import random
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple
from itertools import count
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
class DQN(object):
def __init__(self,**kw_args):
self.device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.env=gym.make("CartPole-v0")
self.Transition=namedtuple("Transition",("state","action","next_state","reward"))
self.BATCH_SIZE=128
self.GAMMA=0.999
self.EPS_START=0.9
self.EPS_END=0.02
self.EPS_DECAY=200
self.TARGET_UPDATE=5
self.MEMORY_CAPACITY=100000
self.policy_net=self.Net().to(self.device)
self.target_net=self.Net().to(self.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.optimizer=optim.Adam(self.policy_net.parameters())
self.memory=self.memory_create(self.MEMORY_CAPACITY)
self.episodes_durations=[]
class Net(nn.Module):
def __init__(self):
super(DQN.Net,self).__init__()
self.fc1=nn.Linear(12,16)
# self.bn1=nn.BatchNorm1d(8)
self.fc2=nn.Linear(16,16)
# self.bn2=nn.BatchNorm1d(16)
self.fc3=nn.Linear(16,2)
def forward(self,x):
# x=F.relu(self.bn1(self.fc1(x)))
# x=F.relu(self.bn2(self.fc2(x)))
x=torch.cat([x,pow(x,2),0.1/x],1)
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def memory_create(self,capacity):
outter_class=self
class Memory(object):
def __init__(self,capacity):
self.memory=[]
self.capacity=capacity
self.tail=0
def push(self,*args):
a_piece_of_memory=outter_class.Transition(*args)
if len(self.memory)threshold:
with torch.no_grad():
return self.policy_net(state).max(1)[1].view(1,1)
else:
return torch.tensor(random.randint(0,1),device=self.device,dtype=torch.long).view(1,1)
def optimize_model(self):
if len(self.memory)= 50:
means = durations_t.unfold(0, 50, 1).mean(1).view(-1)
means = torch.cat((torch.zeros(49), means))
plt.plot(means.numpy())
plt.pause(0.001) # pause a bit so that plots are updated
if __name__=="__main__":
dqn=DQN()
dqn.train(400)